데이터베이스 인덱싱의 개념을 검색해보면 위키에서 "테이블에 대한 동작의 속도를 높여주는 자료 구조" 라는 말로 정의하고 있다. 근데 이것만 봐서는 인덱싱이 정확하게 무엇인지는 파악하기가 솔직히 힘들 것이다. (나부터가 "그래서 그게 뭔데, 어떻게 하는건데." 라는 생각부터 먼저 들었었다.. 😱 ) 그래서 데이터베이스에서 대략적으로 인덱스가 어떤 개념이고 어떻게 사용하는지, 또 왜 사용하는 것인지 간단하게 한 번 정리해보았다.
우리는 데이터베이스를 이용해서 다양한 데이터를 저장한다. 만약 소규모 프로젝트라면 계속되서 축적되는 데이터들의 양이 크게 문제가 되지 않지만, 조금만 규모가 커지더라도 테이블의 수와 데이터의 수는 기하급수적으로 증가하게 된다. 데이터의 수가 수백, 수천만 개 수준만 되더라도, 데이터를 조회를 위해 처음부터 끝까지 검색해야 한다면 시간이 오래 걸릴 수 밖에 없을 것이다. 그렇다면 조회를 좀 더 효율적으로 할 수 있는 방법이 있지 않을까? 라는 생각이 들 수 있는데, 바로 이 때 쓰이는 것이 인덱스다.
데이터베이스 인덱싱은 말 그대로 데이터베이스에 색인을 남기는 것이다. 색인을 통해서 검색의 범위를 줄이는 것이 조회에 있어 훨씬 효과적이기 때문이다. 물론 항상 색인을 남기는 방식이 효율적이란 것은 아니다. 위에서 언급한 것처럼 색인은 큰 규모의 데이터를 다루고, 또 조회를 자주 할 경우가 많을 때 효과적인 방법이다. 예를들어 우리가 가끔 읽는 10페이지 정도의 얇은 책자에 색인을 달아둔다면 소모되는 시간이나 자원에 비해서 크게 효과가 있다고 보기는 힘들 것이다. 하지만 우리가 자주 읽어야 할 2000페이지의 전공 서적에 색인을 달아둔다면 엄청난 효율을 얻게 된다.
인덱스는 인덱스-데이터레코드로 구성되며, 데이터베이스에서 인덱스의 종류는 대표적인 b-tree 인덱스를 포함해 r-tree 인덱스, 비트맵 인덱스 등 다양한 방식이 존재한다.
다음은 대략적인 인덱스의 형태를 나타낸 그림으로, EMPLOYEE라는 테이블에 대해 EMPNO 컬럼에 인덱스를 걸어주었을 때 EMPNOINDEX라는 인덱스 값에 따른 포인터 값이 실제 데이터 레코드를 향하고 있음을 확인할 수 있다.
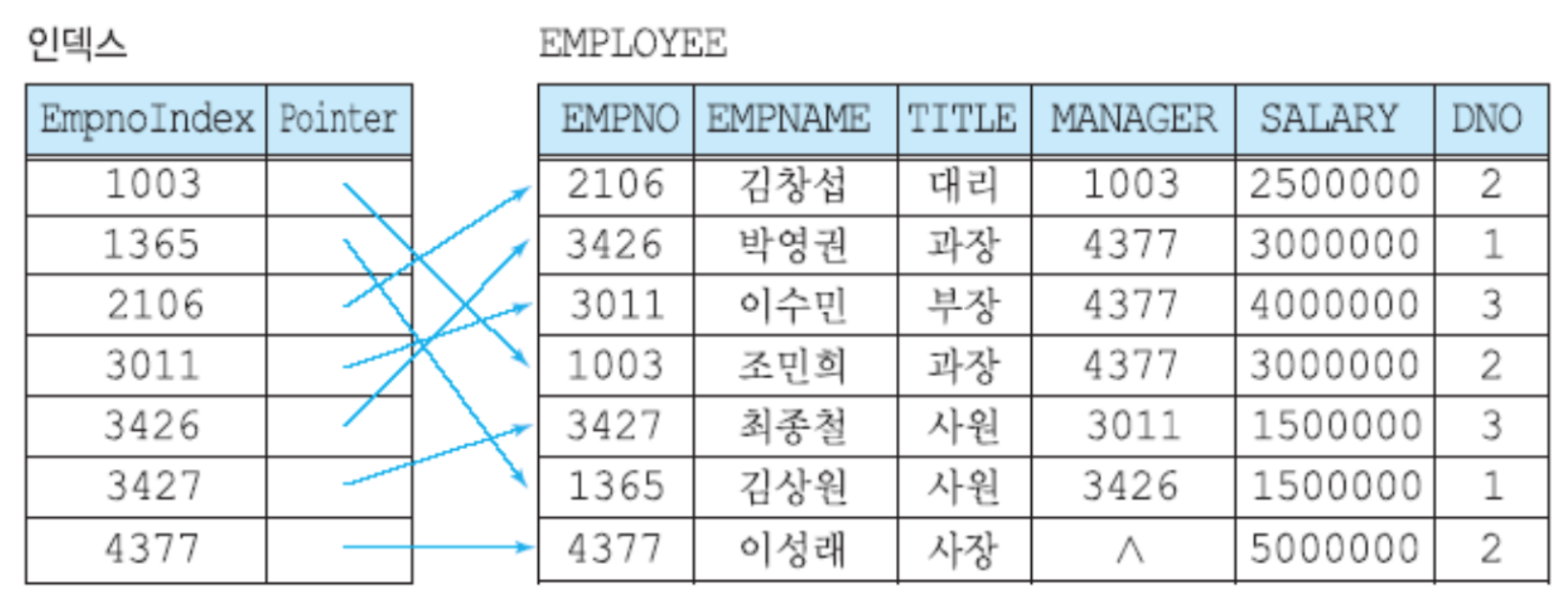
하지만 기본적으로 어떤 형태란 건 이해가 가능했지만, 나같은 경우에는 인덱스 값을 정하는 기준은 또 무엇이 될 것인지에 대해 의문이 들었다. 이를 설명하기 위해서 레퍼런스 링크들을 참고해 좀 더 이해하기 쉬운 예시를 작성해보았다.
| rowid | name | category | location |
| 1 | 이펙티브 자바 | java | A |
| 2 | 혼자 공부하는 파이썬 | python | C |
| 3 | 이것이 c++이다 | c++ | F |
| 4 | 모던 자바스크립트 입문 | javascript | E |
| ... | ... | ... | ... |
| 19999 | 코어 자바스크립트 | javascript | K |
| 20000 | 자바의 정석 | java | U |
우리가 도서관으로 가서 자바스크립트에 대한 책을 전부 찾으려 한다고 가정해보자. 먼저 프로그래밍 언어 섹션으로 갔고, 해당 테이블의 이름은 BookLibrary 라고 해보자. 빠르게 책을 찾고 싶었지만 이미 그 곳에서만 20000개나 되는 책이 존재했고 다양한 언어에 대한 책들이 입고순으로 마구 뒤섞여 있었다.
만약 우리가 인덱스가 없는 상황에서 자바스크립트 관련 도서만을 찾아 내려면, 우리는 SELECT name, location FROM BookLibrary WHERE category='javascript'라는 쿼리문을 작성했을 때 20000개의 도서에 관한 데이터를 모두 확인해야 할 것이다.
그렇다면 좀 더 효율적으로 찾기 위해 인덱스를 만드려면 어떻게 해야할까? 우리는 javascript에 관한 책들을 찾고 싶으므로, catogory라는 컬럼을 기준으로 인덱스를 정리해 볼 수 있을 것이다. 여기서 우리는 인덱스를 나누는 기준이 WHERE에 들어가는 값들이 되는 것을 자연스럽게 이해할 수 있다. (참고로, 예시에서 category와 함께 rowid를 기준으로 인덱스를 정리한 이유는, rowid가 데이터베이스에서 고유적으로 생성되는 값이기 때문에 해당 값만 찾는다면 포인터와 같이 조회에서 가장 효율적으로 사용될 수 있기 때문이다.)
| category | rowid |
| ... | |
| c++ | 3 |
| ... | |
| java | 1 |
| java | ... |
| java | 20000 |
| javascript | 4 |
| javascript | ... |
| javascript | 19999 |
| python | 2 |
| ... | ... |
하지만 위 처럼 인덱스를 정리해놓는다면 우리는 문자열 순으로 정리된 인덱스에서 javascript라는 조건의 값들을 알아낸 후, 더 이상 데이터가 없다고 판단될 경우에 바로 조회를 종료할 수 있을 것이다.
인덱스를 사용해서 javascript를 찾아내고 싶다면, java와 javascript, javascript와 python의 경계를 찾아내 그 사이의 값들에 정리된 javascript와 연관된 데이터들의 rowid를 모두 가지고 와서 빠르게 찾아낼 수 있기 때문이다. (이 과정에서 b-tree 방식이 사용될 것이다.) 만약 여기서 각 프로그래밍 언어마다 가장 처음 입고된 책들을 각 카테고리의 목차라고 생각해본다면 다음과 같이 더 간단하게도 압축이 가능하다.
| category | rowid |
| c++ | 3 |
| java | 1 |
| javascript | 4 |
| ... | ... |
이 때 인덱스는 데이터를 위에서 언급한 b-tree 구조로 저장하기 때문에 좀 더 효율적으로 검색이 가능하다. b-tree는 트리 구조의 해당하는데, 자료 구조 관련이기 때문에 쓰다보면 내용이 너무 길어질 것 같아 다음 링크를 참고해보는 것을 추천한다. (그림으로 설명되어 있어서 이해하기 엄청 편했다!)
[자료구조] 그림으로 알아보는 B-Tree
B트리는 이진트리에서 발전되어 모든 리프노드들이 같은 레벨을 가질 수 있도록 자동으로 벨런스를 맞추는 트리입니다.
velog.io
물론 이런 인덱스는 사용자가 하나하나 찾아서 작성할 필요는 없고, 우리는 명령어만 입력해주면 된다. CategoryIdx라는 이름으로 BookLibrary의 category 컬럼을 기준으로 한 오름차순 인덱스를 만들고자 한다면 쿼리문을 작성할 수 있다. (인덱스에 포함되는 필드의 정렬 순서를 ASC, DESC로 설정할 수 있다.)
CREATE INDEX CategoryIdx On BookLibrary(category ASC);
참고로 아래와 같은 쿼리문을 이용하면 해당 테이블이 가지는 모든 인덱스를 확인할 수 있다. 반환되는 값에 대한 자세한 내용은 첨부한 링크에서 확인이 가능하다.
SHOW INDEX FROM BookLibrary;
Reference
'DEVELOP > Database' 카테고리의 다른 글
| [Database] 트랜잭션의 개념 및 단계 (0) | 2021.06.21 |
|---|
